Predictive Analytics in Insurance
- Alex Moskvin
- May 21
- 16 min read

Predictive analytics is transforming the insurance industry, enabling companies to address challenges such as fraud detection, risk assessment, and customer personalization with greater data-driven precision. According to Nasdaq, insurance fraud in the United States alone results in an estimated $308.6 billion in annual losses, increasing premiums by an average of $900 per consumer.
By leveraging historical and real-time data through advanced analytics solutions and custom insurance software, insurers can improve operational accuracy, streamline decision-making, and respond more effectively to market changes. Predictive analytics not only strengthens fraud prevention efforts but also enhances customer experiences and supports more agile, data-informed business strategies across the industry.
Why should insurers invest in predictive analytics? What are the most effective ways to apply it? And how can companies overcome the challenges associated with implementation? Let's explore.
Overview
Insurance is often defined as "a promise to provide compensation in the future if certain events occur within a specified period". Unlike most products, whose costs are known before sale, insurance operates differently because the true cost of an insurance policy is uncertain at the time of purchase. As a result, selling insurance inherently involves significant financial risk.
At its core, product pricing is based on the relationship between cost and profit. In the insurance industry, however, the primary challenge lies in accurately estimating future costs. Over the years, insurers have developed numerous tools, methodologies, and actuarial models to improve pricing accuracy. More recently, the rise of big data, predictive analytics, advanced data processing, and artificial intelligence (AI) has significantly expanded insurers' analytical capabilities.
Despite these advancements, insurance pricing remains highly complex. For example, the U.K. motor insurance market reported an underwriting profit in 2015 for the first time since 1994. This highlights how difficult profitability and risk management can be in the insurance sector.
The primary objective of insurance pricing is to establish premiums that are adequate, fair, and competitive. From a customer-centric perspective, pricing models should also be transparent, stable over time, responsive to economic changes, and aligned with effective loss-control strategies that keep coverage affordable. Balancing these often competing requirements creates substantial operational and financial challenges for insurers.
To determine appropriate premiums, insurers must address numerous uncertainties throughout the customer journey (Figure 1), including:
How risky is a particular customer?
How can insurers improve customer retention?
How likely is a customer to file a claim, and what might the claim amount be?
Can potentially fraudulent behavior be identified early?
How can insurers encourage customers to purchase additional products or services?
As insurance operations become more sophisticated, the number and complexity of these questions continue to grow.

Figure 1: Customer Interactions Throughout the Customer Journey
Developing premiums that are both competitive and financially sustainable is essential for answering these questions and maintaining long-term customer relationships. As a result, insurance pricing, which is often referred to as ratemaking, remains one of the most important applications of data science in the insurance industry.
Pricing and claims management are the two core pillars of insurance analytics. Together with fraud detection, they form the foundation of modern insurance innovation and drive the rapid evolution of insurance technology solutions.
Table 1 illustrates how data science can be utilized across these three insurance concepts and deal with various business challenges at different stages in the customer lifecycle.
Table 1: Leveraging Data Science for Insurtech
Segment | Challenges | Analytics Solution | Modeling Approach | Business Benefits |
|---|---|---|---|---|
Pricing | The ultimate cost of an insurance policy is not known at the time of sale | Customer level Ratemaking (risk-based pricing) | AI-enhanced Generalized linear models (GLMs), gradient boosting models, telematics-based risk scoring, real-time underwriting models | Adequate and fair pricing so the premium = loss + profit |
Understanding competitive market and its dynamics | Market-based pricing models including: conversion, demand and retention models | Propensity models, customer segmentation, survival analysis, behavioral analytics | Expanding the customer base, competitive advantage | |
How valuable are my customers? | Customer lifetime value | Predictive CLV modeling, segmentation analytics, churn prediction models | Optimal marketing campaigns | |
What is a customer pricing tolerance? | Price elasticity | Optimization algorithms, reinforcement learning, dynamic pricing models | Maximizing profit | |
Claims | Reduce high operational/ IT cost and maintain customer satisfaction | Claims management framework including first notification of loss | Holistic approach utilizing: NLP, OCR, workflow automation, computer vision, predictive claims severity models | Real-time decision-making, monetization |
Fraud Detection | Application and claims fraud detection | Fraud detection framework | Holistic approach utilizing: anomaly detection, graph analytics, link analysis, black lists, fraud scoring models, explainable AI | Minimizing loss |
The successful development, implementation, and use of predictive models in insurance depend on analytics platforms capable of supporting a wide range of functions. These include extract, transform, and load (ETL) processes, data preparation and visualization, model development and validation, deployment, testing, production management, and ongoing performance monitoring.
To balance functionality and cost, insurers often rely on a combination of commercial and open-source tools. However, this approach requires careful planning, as integrating multiple technologies can become time-consuming, resource-intensive, and potentially lead to fragmented or suboptimal solutions.
Adequate, Fair, and Competitive Insurance Pricing
When looking for an attractive policy quotation, prospective customers usually ask, which insurance? In competitive insurance markets, insurers need to develop a bespoke pricing methodology to ensure their policy premiums are adequate so they cover expected losses and incurred expenses, fair so the premiums are associated with expected losses and expenses, and competitive so they attract new customers and retain existing ones.
Ratemaking or risk-based pricing remains an essential step and the key element of insurance pricing. Modern actuarial pricing techniques and methodologies depend on insurance type, data availability, and extensive regulatory, marketing, and operational constraints. However, the insurance pricing landscape is rapidly evolving due to advances in artificial intelligence, telematics, cloud computing, and real-time analytics capabilities.
Traditional pricing methods are increasingly complemented by AI-enhanced underwriting and personalized risk-based pricing models. Insurers now combine historical policy and claims data with external and behavioral data sources such as telematics, IoT devices, geospatial information, credit attributes, digital interactions, and customer behavioral patterns. These additional data sources allow insurers to move from static pricing models toward more dynamic and individualized pricing strategies.
Modeling approaches range from traditional actuarial and statistical techniques to advanced machine learning and optimization frameworks. Modern pricing ecosystems often combine Generalized Linear Models (GLMs) with machine learning techniques such as gradient boosting, telematics-based risk scoring, propensity modeling, customer segmentation, survival analysis, churn prediction, reinforcement learning, and dynamic pricing optimization models. Statistical models typically focus on data fitting and interpretability through explicit mathematical relationships, whereas machine learning methods focus on pattern recognition and predictive performance with fewer assumptions about underlying data distributions.
Recognizing the most appropriate modeling technique in the modern analytics landscape remains challenging and requires organizations to balance multiple factors, including predictive accuracy, interpretability, regulatory compliance, fairness, operational scalability, deployment complexity, real-time response requirements, and ongoing model monitoring. In practice, insurers increasingly adopt hybrid modeling architectures that combine the transparency and governance advantages of actuarial models with the predictive power of machine learning systems.
Example with GLM
Despite rapid advances in AI and machine learning, the GLM remains the de facto standard across much of the insurance industry. GLMs continue to be widely adopted because they are interpretable, regulator-friendly, computationally efficient, and provide strong control over rating factor selection. In addition, GLM-based rating algorithms (Table 2) are relatively easy to operationalize and integrate with actuarial expertise, regulatory requirements, marketing considerations, and business constraints.
Table 2: GLM-Based rating relatives and rating algorithm (illustration)
Base Rate | $500 | Rating Algorithm | |
|---|---|---|---|
Rating Factor | Level | Relativity | Pure Premium = Base Rate |
Territory Zone | 1 | 3.18 | *Territory Zone |
2 | 1.91 | ||
3 | 0.71 | ||
4 | 1.00 | ||
Vehicle Age | 1 | 2.38 | *Vehicle Age |
2 | 1.44 | ||
3 | 1.0 | ||
Engine Power | 1 | 0.37 | *Engine Power |
2 | 0.72 | ||
3 | 1.00 | ||
4 | 1.26 | ||
5 | 1.50 | ||
6 | 2.96 | ||
7 | 4.41 | ||
Bonus | 1 | 0.58 | *Bonus |
2 | 0.79 | ||
3 | 1.00 |
Here the insurer starts with a Base Rate = $500
This is the starting premium before adjusting for risk.
The premium changes depending on customer characteristics:
Rating Factor | Meaning |
|---|---|
Territory Zone | Where the driver lives |
Vehicle Age | Age of the vehicle |
Engine Power | Vehicle horsepower/risk |
Bonus | No-claim discount level |
Each factor has levels and a relativity. Relativity measures how risky a customer is compared to the average risk:
Relativity > 1.00 → higher risk → premium increases
Relativity < 1.00 → lower risk → premium decreases
Relativity = 1.00 → average risk
Example:
Engine Power Level | Relativity | Meaning |
1 | 0.37 | Very low risk |
7 | 4.41 | Very high risk |
So a powerful car increases premium significantly.
The algorithm multiplies the base rate by all selected relativities.

Suppose a customer has:
Factor | Level | Relativity |
Territory Zone | 2 | 1.91 |
Vehicle Age | 2 | 1.44 |
Engine Power | 4 | 1.26 |
Bonus | 1 | 0.58 |

So this customer would pay approximately $1004.
This is a traditional actuarial pricing structure commonly used before advanced machine learning methods like LightGBM or XGBoost became popular.
Example with GBT
Modern insurers are progressively augmenting GLM frameworks with AI-driven components to improve pricing precision, customer retention, and underwriting speed. Gradient boosting models (GBMs) and telematics-based models are increasingly used for personalized pricing, propensity and survival models support customer retention and lifetime value estimation, while optimization and reinforcement learning techniques enable real-time pricing adjustments based on market conditions and customer behavior. This transition reflects the broader evolution of insurance pricing from static actuarial frameworks toward AI-enabled, real-time, and customer-centric pricing ecosystems.
Idea of GBT is instead of calculating premium only by:

we train a model to learn the relationship from data:

Table 3: GBM example training data
Customer | Territory | Vehicle Age | Engine Power | Bonus | Actual Premium, USD |
A | 2 | 2 | 4 | 1 | 1004.00 |
B | 4 | 3 | 3 | 3 | 500.00 |
C | 1 | 1 | 7 | 1 | 4063.00 |
D | 3 | 2 | 5 | 2 | 779.00 |
E | 2 | 1 | 6 | 1 | 2350.00 |
The Actual Premium can come from historical policy data or from the GLM formula.
Let's use LightGBM as an example model. LightGBM builds many small trees. Each tree improves the previous prediction.
Step 1: Start with average premium
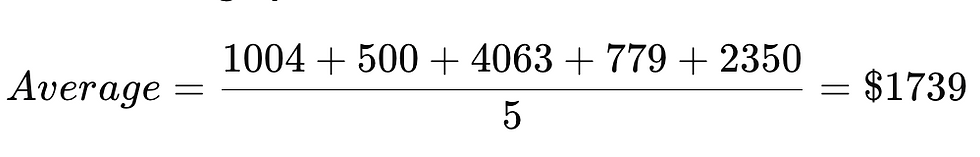
So the first prediction for everyone is $1739.
Customer | Actual | Initial Prediction | Error |
A | 1004 | 1739 | -735 |
B | 500 | 1739 | -1239 |
C | 4063 | 1739 | 2324 |
D | 779 | 1739 | -960 |
E | 2350 | 1739 | 611 |
Step 2: First Decision Tree Learns the Errors
Example tree:
If Engine Power >= 6:
add +1468
Else if Bonus = 1:
add -62
Else:
add -1100Step 3: Updated Predictions
Using learning rate = 0.10:
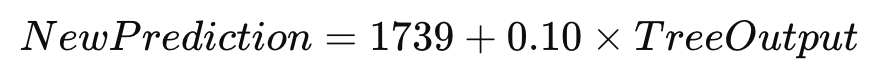
Customer | Tree Output | New Prediction, USD |
A | -62 | 1733.00 |
B | -1100 | 1629.00 |
C | +1468 | 1886.00 |
D | -1100 | 1629.00 |
E | +1468 | 1886.00 |
The model repeats this process many times. Later trees keep correcting the remaining errors.
After many trees:
Customer | Actual Premium, USD | GBDT Predicted Premium, USD |
A | 1004.00 | 980.00 |
B | 500.00 | 540.00 |
C | 4063.00 | 3950.00 |
D | 779.00 | 820.00 |
E | 2350.00 | 2410.00 |
Key Difference from GLM
GLM Rating Table | GBDT / LightGBM |
Uses fixed relativities | Learns patterns from data |
Multiplicative formula | Uses many decision trees |
Easier to explain | Often more accurate |
Assumes smooth factor effects | Captures interactions automatically |
Example interaction:
High engine power + low bonus + risky territory
= much higher premiumA GLM needs this interaction added manually, but LightGBM can learn it automatically.
Back to Pricing
The result of the ratemaking process is a predicted technical price (i.e., pure premium) that reflects expected claim frequency, claim severity, exposure characteristics, and overall portfolio risk. When modeled accurately, the technical premium should provide an adequate price to cover expected losses. The technical price is subsequently adjusted to include underwriting expenses such as acquisition costs, commissions, taxes, reinsurance costs, capital requirements, and target underwriting profit.
Traditionally, insurance pricing relied primarily on actuarial risk-based pricing with limited incorporation of competitive and behavioral market dynamics. However, this approach has become increasingly insufficient in highly competitive and digitally enabled insurance markets. Modern insurers are transitioning toward more sophisticated and holistic pricing methodologies that integrate actuarial expertise with artificial intelligence, machine learning, telematics, customer behavior analytics, and real-time market intelligence.
A holistic pricing framework is now essential for achieving sustainable competitive advantage. Insurers increasingly leverage diverse internal and external data sources including telematics, IoT devices, geospatial information, digital interactions, and behavioral signals - to improve pricing precision, personalize customer offerings, optimize retention, and enhance portfolio profitability. As insurers deepen their analytical capabilities and expand access to real-time data ecosystems, they are better positioned to uncover actionable business insights and develop AI-driven, customer-centric pricing strategies.

Figure 2: Insurance Pricing Process
In this context, relying solely on traditional risk-based pricing is comparable to operating with limited visibility into the broader insurance ecosystem - it constrains insurers' ability to fully leverage modern data assets and AI-driven analytics capabilities. While actuarial ratemaking remains essential for establishing adequate technical premiums, it does not necessarily produce competitive, personalized, or commercially optimized pricing. To remain competitive in increasingly digital and data-driven insurance markets, insurers must augment traditional pricing methodologies with dynamic customer segmentation, behavioral analytics, demand prediction, real-time simulation, and AI-driven price optimization.
Ratemaking combines actuarial expertise with advanced analytics and diverse internal and external data sources. In addition to historical claims and policy data, insurers increasingly incorporate telematics, IoT data, geospatial information, behavioral signals, and external market indicators to calculate personalized risk-based premiums. Contemporary pricing models often integrate GLMs with machine learning techniques such as gradient boosting, telematics-based risk scoring, and predictive underwriting models to improve pricing precision and underwriting performance.
Customer segmentation plays a critical role in identifying customers and portfolios eligible for pricing actions such as premium increases, discounts, retention offers, or targeted acquisition campaigns. Modern segmentation approaches extend beyond traditional rule-based methods and increasingly rely on AI-driven customer analytics, including propensity modeling, survival analysis, customer lifetime value estimation, churn prediction, and behavioral segmentation. These approaches help insurers balance profitability objectives with fairness, customer retention, and regulatory requirements.
Competitive pricing has evolved into a broader customer demand and behavioral prediction framework. Rather than focusing exclusively on competitor pricing, insurers increasingly model customer conversion probability, retention likelihood, price elasticity, and market responsiveness. Demand models, propensity models, and elasticity analytics enable insurers to better understand how customers respond to different pricing strategies and market conditions. In highly competitive digital insurance markets, these models are often deployed in near real-time environments, making scalability, response latency, and deployment efficiency critical considerations when selecting modeling approaches.
The next stage in the pricing process involves real-time pricing simulation and scenario analysis. Insurers use what-if simulations and stress-testing frameworks to evaluate the impact of pricing decisions on customer acquisition, retention, portfolio profitability, risk exposure, and regulatory fairness constraints. These simulations help organizations assess trade-offs across multiple business objectives before deploying pricing changes into production environments.
The final stage of the pricing process price optimization. This step focuses on identifying pricing strategies that maximize long-term portfolio value while balancing competitiveness, customer retention, profitability, and regulatory compliance. Modern optimization frameworks increasingly leverage reinforcement learning, optimization algorithms, and multi-objective optimization techniques to dynamically determine personalized premiums under predefined business and regulatory constraints.
Unlike traditional linear pricing workflows, modern insurance pricing architectures operate as continuous learning systems. Pricing models are constantly refined using new customer interactions, claims outcomes, conversion behavior, retention metrics, and market intelligence. This continuous feedback loop enables insurers to improve predictive accuracy, monitor model performance, maintain fairness and explainability, and adapt pricing strategies in near real time to changing customer and market conditions.

Figure 3: Price Optimization Problem
Figure 4 is an illustration of an optimization model that offers premium discounts of up to 20% on the risk-based price. Depending on the underlying demand model, the premium discount distribution ranges from no-discount to a maximum 20% discount.
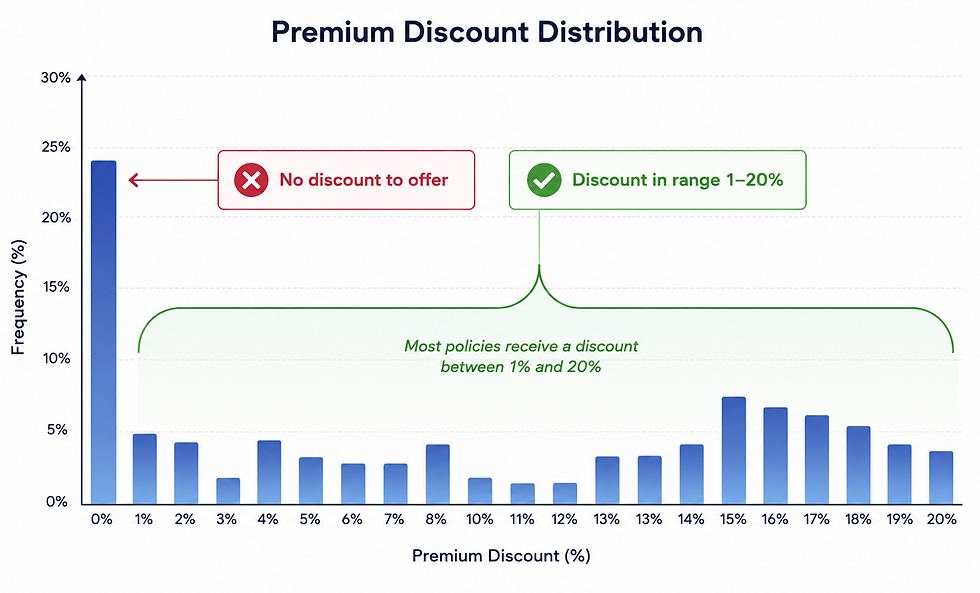
Once the optimal scenario is selected, the complete pricing solution is ready for deployment, implementation, and testing. This includes the risk-based model, the demand model, and the optimization model. The complete model suite can be implemented on a single rating engine or hosted across multiple engines. After a rigorous testing process, the pricing solution is ready for a racing competition.
Claims Management
U.S. insurance industry figures remain staggering. Property and casualty insurance fraud alone is estimated to cost the U.S. economy more than $300 billion annually, with tens of billions attributed specifically to fraudulent auto and property claims.
In the auto insurance sector, claim severity and repair complexity continue to rise due to inflation, advanced vehicle electronics, calibration requirements, and increasing total-loss frequency. Recent industry reports show that total loss frequency in collision claims has increased to nearly 23-29% of all claims, while catastrophic weather events and rising repair costs continue to place pressure on insurers’ underwriting profitability.
At the same time, insurers face growing operational challenges, including high claims handling costs, increasing customer expectations for digital-first service, rising fraud sophistication, and the need for real-time claims decisioning. The rapid adoption of generative AI has introduced additional fraud risks, with industry estimates suggesting that 25-30% of suspicious claims artifacts may now involve AI-generated or manipulated documents and images. Legacy systems, fragmented third-party integrations, regulatory complexity, and high infrastructure modernization costs further contribute to operational inefficiencies and increased expense ratios.
Despite substantial investments in claims automation and fraud prevention, there remains significant opportunity to improve customer experience, operational efficiency, and claims accuracy through AI-native claims ecosystems. Modern platforms increasingly integrate predictive analytics, real-time data orchestration, computer vision, telematics, IoT devices, geospatial intelligence, and generative AI to streamline claims management and support intelligent decision-making throughout the claims lifecycle. Machine learning and AI help insurers improve reserve estimation, fraud detection, claims severity prediction, and resource allocation while reducing subjectivity and manual processing.
One of the most important areas of InsurTech innovation remains First Notice of Loss (FNOL). FNOL represents the first and often most critical stage of the claims journey, where insurers must rapidly evaluate policy coverage, assess fraud risk, estimate claim severity, prioritize claims triage, and initiate customer engagement. Failure to manage FNOL effectively can significantly increase operational costs and negatively impact customer satisfaction and retention.
Modern FNOL ecosystems are increasingly real-time, cloud-native, and AI-driven. These platforms combine predictive models, conversational AI assistants, computer vision, telematics data, third-party integrations, and intelligent workflow orchestration to support claims adjusters and automate low-severity claims processing. Claims models may include total-loss prediction, bodily injury severity estimation, reserve forecasting, fraud detection, repair cost estimation, and recovery likelihood prediction. Increasingly, these models operate continuously through API-first architectures and event-driven systems capable of near real-time scoring and decisioning.
Dynamic AI-driven workflows can further personalize the claims process. For example, elevated fraud scores may trigger enhanced verification procedures, additional documentation requests, or specialized investigative workflows, while low-risk claims may qualify for straight-through processing and automated settlement. Conversational AI agents and GenAI-powered virtual adjusters are increasingly used to guide customers through self-service claims experiences available anytime and anywhere.
Although adoption of AI-powered claims ecosystems continues to accelerate, insurers still face implementation challenges related to data quality, legacy infrastructure modernization, cybersecurity, regulatory compliance, explainability, and AI governance. Nevertheless, the demand for intelligent claims decision-support systems continues to grow as insurers seek to reduce operational costs, improve claims efficiency, strengthen fraud prevention, and deliver faster, more customer-centric claims experiences.
Implementation of Predictive Analytics With Plexteq
Implementing predictive analytics in insurance requires a structured approach to ensure alignment with business goals, seamless integration with existing systems, and reliable performance. Plexteq follows a comprehensive process to guide insurers through each phase, leveraging deep domain expertise and technical proficiency to deliver impactful results.

1. Discovery Phase
Data specialists from Plexteq begin by aligning predictive analytics initiatives with your business objectives. Our experts engage with stakeholders, identify goals for underwriting, fraud detection, and customer retention, and evaluate your existing technology landscape. Plexteq’s team assesses data sources, infrastructure, and other prerequisites to ensure the project is built on a solid foundation.
2. Data assessment and preparation
Next, we conduct a detailed audit of your data to identify gaps, inconsistencies, and enhancement opportunities. Our experts consolidate data from various sources, clean, and transform it to meet analytics requirements so that it is ready for modeling. Through normalization and enrichment, we create a dataset that captures essential insights into risk and customer behavior, tailored to the insurance industry.
3. Model design and customization
Plexteq data scientists develop predictive models tailored to your needs, whether for optimizing underwriting, detecting fraud, or enhancing customer engagement. These models use advanced ML algorithms to extract actionable insights from large datasets. Model customization focuses on aligning with specific insurance processes to provide highly accurate predictions that support informed decision-making.
4. Pilot testing and validation
Our data experts test each predictive model in a controlled environment, ensuring it performs accurately and consistently across different scenarios. This pilot phase fine-tunes model parameters and validates performance in realistic conditions, minimizing the risk of inaccuracies in production. Pilot testing confirms that the models meet business expectations and regulatory requirements before being deployed enterprise-wide.
5. Deployment and integration
Our team integrates the validated models into your core insurance systems, seamlessly embedding them in underwriting, claims management, and customer service workflows. This integration enables real-time insights across operations, allowing teams to make data-driven decisions at every step. The experts from Plexteq configure each model to function smoothly within your existing processes, maximizing operational efficiency and enhancing service delivery.
6. Continuous monitoring and optimization
After the deployment, Plexteq monitors model performance and adapts the models to reflect new data patterns, industry changes, or evolving risk factors. Regular recalibration ensures the models maintain high accuracy and relevancy as market conditions shift. Plexteq’s continuous optimization approach aligns your predictive analytics solutions with business goals and regulatory standards, providing long-term value.
Challenges in implementing predictive analytics for insurers and Plexteq’s solutions
While predictive analytics in insurance can drive substantial value, businesses often face challenges in implementation. Plexteq addresses each obstacle with targeted solutions, ensuring a smooth transition to data-driven operations.
Legacy systems and data silos
Many insurers rely on outdated, standalone systems that were not designed to work together. These legacy systems create data silos, where valuable information remains isolated in different departments or databases. As a result, insurers struggle to gain a comprehensive view of customer risk, claims history, and fraud patterns.
Plexteq solution: We address this issue by modernizing systems and consolidating data into centralized warehouses or data lakes. These data environments provide an integrated infrastructure that supports seamless data integration, making it easier to build accurate predictive models with comprehensive, high-quality data.
Inconsistent data and governance limitations
Data must be clean, complete, and consistent for predictive analytics to provide reliable insights. However, insurers often deal with incomplete records, outdated information, and data inconsistencies. Poor data quality directly impacts the accuracy of predictive models, leading to unreliable predictions and flawed decision-making.
Plexteq solution: Plexteq tackles this issue by implementing data cleansing processes that standardize and enrich datasets. We also set up data governance frameworks to maintain data quality and compliance over time, ensuring that predictive models work with trustworthy data.
Lack of transparency in model operations
Advanced ML and AI algorithms greatly improve the capabilities of predictive analytics in insurance. However, the complex nature of these models can obscure the logic behind predictions, posing challenges for insurers who require clear, explainable insights to meet regulatory and operational needs.
Plexteq solution: Our data experts address this challenge by designing advanced yet interpretable AI models. Our AI algorithms provide explainable outputs, allowing insurers to see why specific predictions are made. This approach builds trust in predictive insights and aligns with regulatory requirements, allowing insurers to harness the power of advanced AI with clarity and control.
Limited scalability and operational performance
As insurers begin to use predictive analytics more extensively, the volume and complexity of data grow. Predictive models can suffer from slow processing times and limited capacity without scalable infrastructure, making them less effective in high-demand situations.
Plexteq solution: Plexteq helps insurers implement scalable cloud solutions and high-performance infrastructure, ensuring that predictive models can handle increasing data loads without compromising on speed or accuracy. This approach allows insurers to scale predictive capabilities seamlessly as their data needs expand.
Wrap-up
Predictive analytics offers insurers tools to manage risks, enhance customer experience, and drive operational efficiency. Data-driven insights allow insurers to anticipate risks, streamline claims processing, and develop innovative products that respond to changing market demands. This proactive approach strengthens insurer-client relationships and boosts operational efficiency, making predictive analytics an essential asset for insurers seeking a competitive edge.
At Plexteq, we help insurers leverage predictive analytics in insurance for sustainable growth and competitive advantage. With a team of 50 professionals, we bring 12 years of industry experience to every project. Our expertise is backed by a successful track record of over 40 data-focused projects, enabling us to address complex challenges in insurance.
Plexteq provides a comprehensive suite of predictive analytics tools, including real-time fraud detection, personalized pricing models, and risk assessment solutions. We also offer customer lifecycle management systems to streamline onboarding and claims, advanced cybersecurity frameworks, and automated document processing for improved operational efficiency.


